Loading Data from MySQL Database with PySpark

I am an Analytical Engineer and I share my learning progress...
Today, we are going to load data from MySQL Database with PySpark. previously I have written on both PostgreSQL and Microsoft SQL Server.
We start by installing MySQL connector.
pip install mysql-connector-python
Next, we start the Spark session.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("MySQL to PySpark") \
.getOrCreate()
Open MySQL workbench to get your server details.
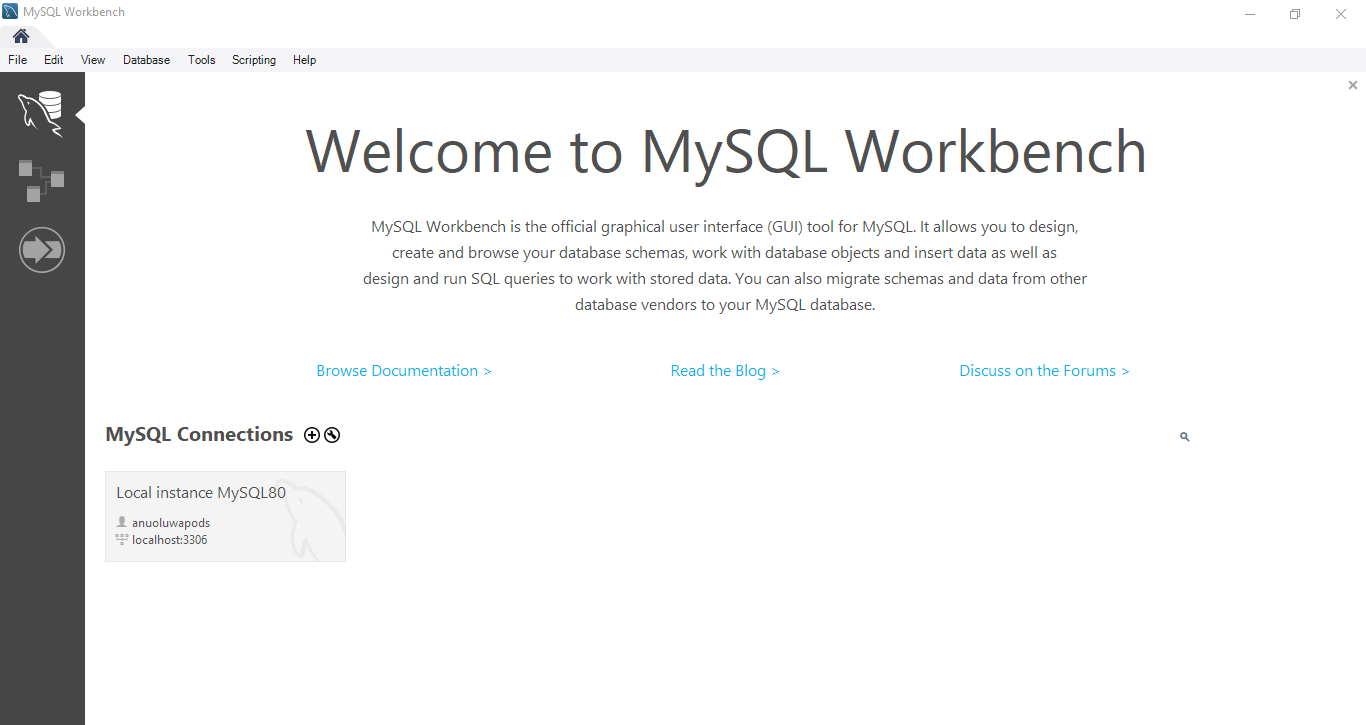
On your Workbench home page, you can see your localhost details called Local Instance.
You can also see MySQL Connections beside this you can see a (Spanner-like icon) click on the icon.
After you click on the icon you will be directed to this page below.
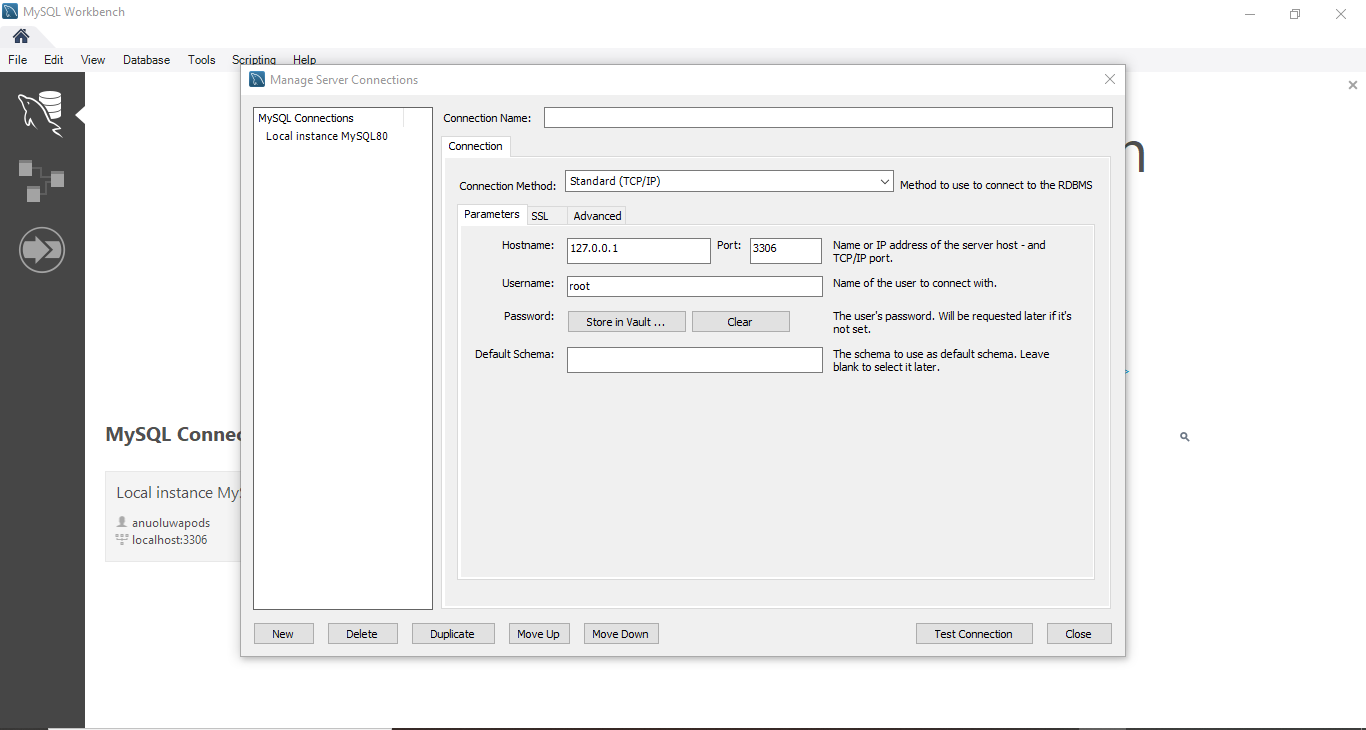
Click on the local instance to get your localhost name default name is “root” and your local host password will be the password you chose while installing MySQL.
Next, we input our local host details into our code.
from pyspark.sql import SparkSession
import mysql.connector
spark = SparkSession.builder \
.appName("MySQL to PySpark") \
.getOrCreate()
db_host = "localhost"
db_port = "3306"
db_name = "DATABASE_NAME"
db_user = "YOUR_USERNAME"
db_password = "YOUR_PASSWORD"
# Create a connection to MySQL using mysql-connector-python
conn = mysql.connector.connect(
host=db_host,
port=db_port,
database=db_name,
user=db_user,
password=db_password
)
# I am using the Database sakila
query = "SELECT * FROM actor"
df_pandas = pd.read_sql(query, conn)
df_spark = spark.createDataFrame(df_pandas)
# Print the schema of the DataFrame
df_spark.printSchema()
# Show the first few rows
df_spark.show()
While using import mysql.connector I ran into an error, you might too and I resolved it by doing this
pip uninstall httpx
The output:

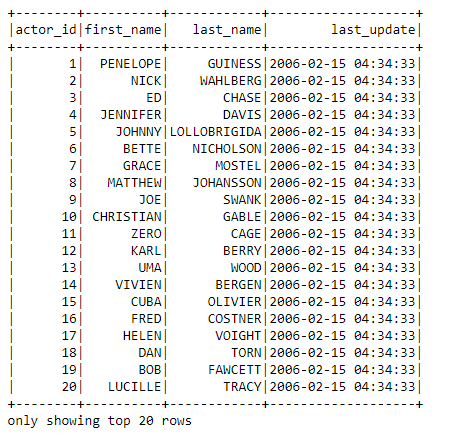
You can always practice extracting data from MySQL with PySpark for your analysis.
Happy Learning!!!!!




