Loading Data From PostgreSQL to PySpark

I am an Analytical Engineer and I share my learning progress...
What is PySpark?
PySpark is the API for Apache Spark it allows real-time and large-scale data preprocessing in Python. It has its own PySpark shell in Python to interactively analyze your data. PySpark supports all Sparks features; Spark SQL, DataFrames, Structured Streaming, Machine Learning, and Spark Core.
Facts about PySpark: It runs programs up to 100x faster than Hadoop MapReduce in memory.
Spark SQL and DataFrames
With Spark SQL you can combine SQL queries and Spark programs easily, the DataFrames can be easily read, written, transformed, and analyzed using Python and SQL.
PySpark applications start with initializing
SparkSession.
Start PySpark on Databricks Community Cloud by signing up here and you can download a guidebook on how to install PySpark on all operating systems here.
Load a Data Frame from a database in PySpark
We are going to practice loading data from the following Database systems using PySpark
PostgreSQL
Microsoft SQL Server
MySQL
SQLite
MongoDB
Load a Data Frame from a PostgreSQL Database with PySpark
Start by installing the PostgreSQL driver
pip install psycopg2
To get the Local Host of your PostgreSQL on Windows.
# Importing the PySpark Libraries into Python
from pyspark.sql import SparkSession
import psycopg2
import pandas as pd
spark = SparkSession.builder \\
.appName("PostgreSQL to PySpark") \\
.getOrCreate()
Connecting to PostgreSQL on Localhost
db_host = "INPUT_YOUR_HOST"
db_port = "INPUT_YOUR_PORT"
db_name = "INPUT_YOUR_USERNAME"
db_user = "INPUT_YOUR_USER"
db_password = "INPUT_YOUR_PASSWORD"
Connecting pyscopg2 and PostgreSQL to query and load data.
conn = psycopg2.connect(
host=db_host,
port=db_port,
dbname=db_name,
user=db_user,
password=db_password
)
query = "SELECT * FROM TABLE"
df_pandas = pd.read_sql_query(query, conn)
df_spark = spark.createDataFrame(df_pandas)
# Print the schema of the DataFrame
df_spark.printSchema()
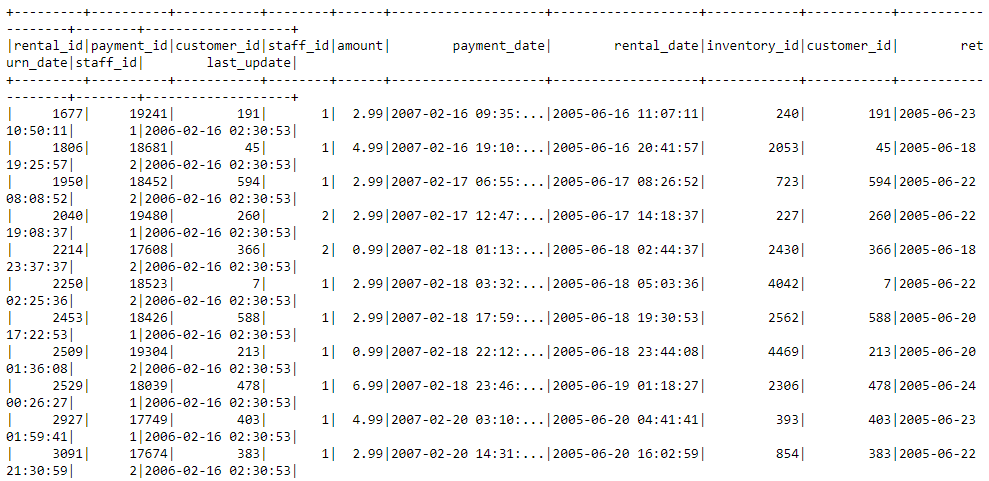
# Show the first few rows
df_spark.show()
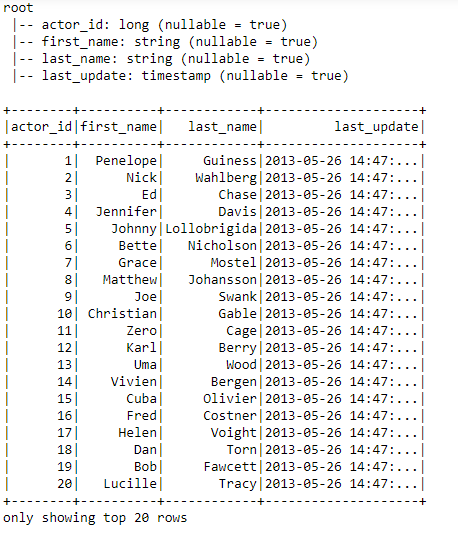
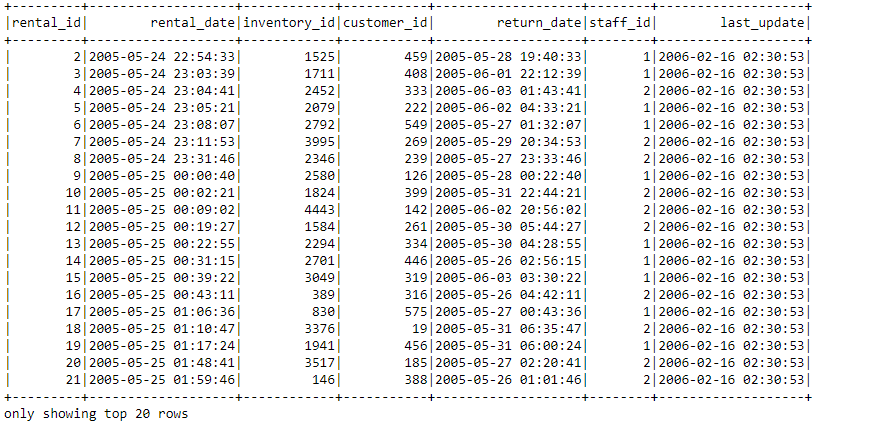
Creating another schema for a new table
query1 = "SELECT * FROM TABLE"
df_pandas1 = pd.read_sql_query(query1, conn)
# Filter rows based on a condition
filtered_df = df_spark.filter(df_spark["amount"] > 4.99)
filtered_df.show()

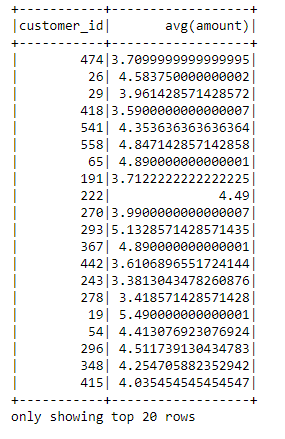
# Group by a column and calculate the average of another column
grouped_df = df_spark.groupBy("customer_id").avg("amount")
grouped_df.show()
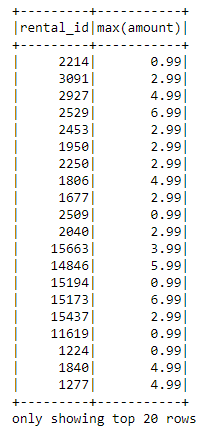
# Perform aggregations
aggregated_df = df_spark.groupBy("rental_id").agg({"amount": "sum", "amount": "max"})
aggregated_df.show()
# Join two DataFrames
joined_df = df_spark.join(df_spark1, on="rental_id", how="inner")
joined_df.show()
# Save the DataFrame as a CSV file
df_spark.write.csv("output.csv")
The next article is on Loading Data From Microsoft SQL Server to PySpark.




