




In this article we are going to learn how to load Dataset from Microsoft SQL Server with PySpark
We start by downloading the pyodbc library with pip
pip install pyodbc
We also need to set up our Microsoft SQL Server Local host server. This guide is important if you are using the Windows authentication in SQL Server
Step 1: Go to the object explorer tab
Right-click on your Windows authentication login profile, (YOUR_USERNAME\SQLEXPRESS) then click on properties.
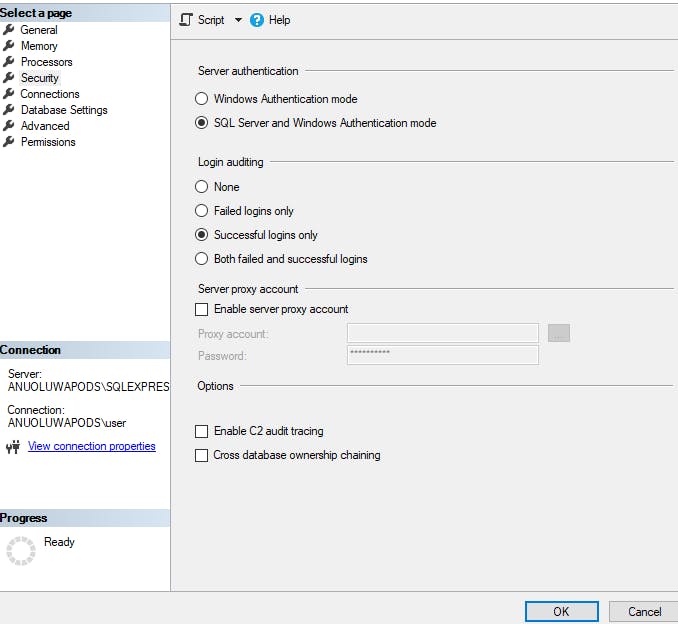
Then click on security and choose SQL Server and Windows Authentication mode. Click Ok
Step 2: Go to the object explorer tab
Right-click on the Security folder (BELOW THE DATABASE FOLDER), Click on New then Click on Login.

Create a new Login name, Choose SQL Server Authentication. Create a new password and Confirm the password. Click ok.
Step 3: Open the SQL Server Configuration Manager
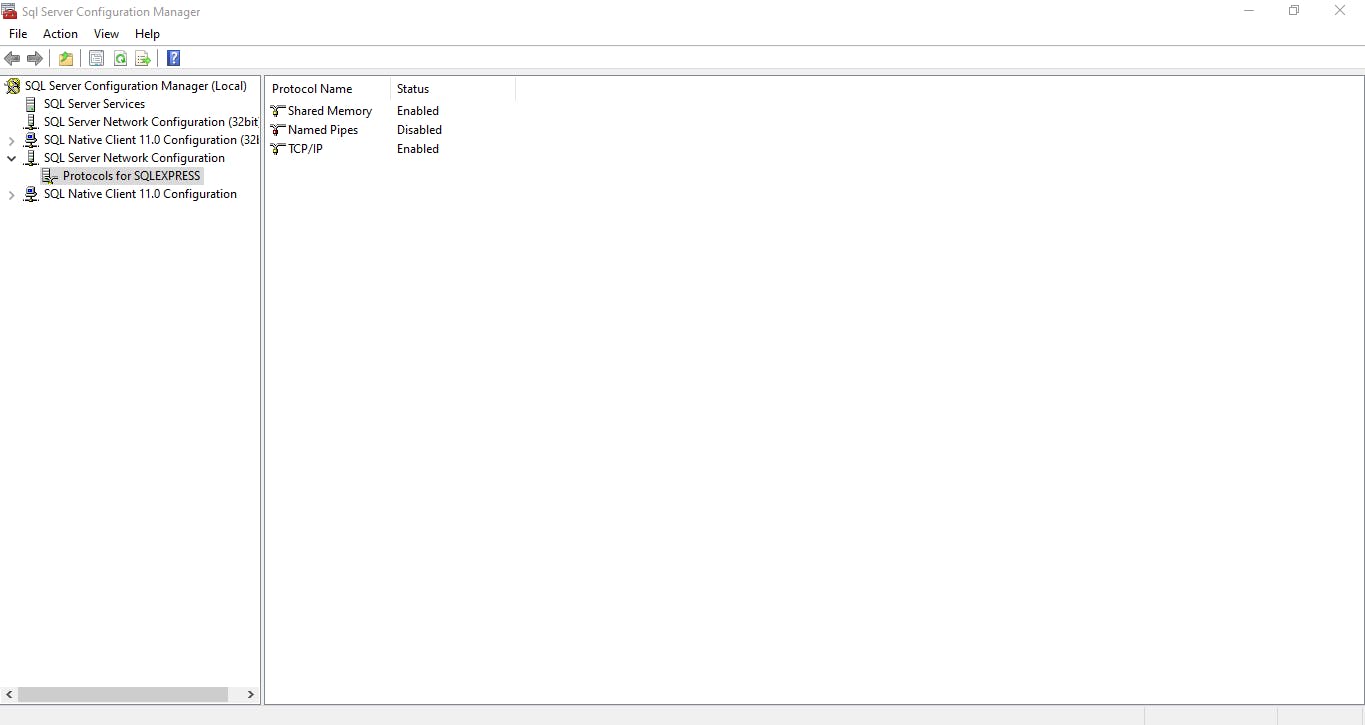
protocols for SQL Server Enable the TCP/IP (Click on the TCP/IP and choose Yes to enable)

The TCP/IP has 2 tabs when opened, the protocol and IP address tab would be displayed. After enabling the TCP/IP, wait a few minutes, then on the IP Address tab scroll down to locate the IPAII The TCP Dynamic port is the port your SQL Server Runs on Copy the value it displays.
Close the server configuration manager.
Step 4: Open the SSMS Studio
While trying to log in the server name should look like this

localhost, YOUR TCP/IP SERVER PORT VALUE
example with a random port number
localhost,1433
login name use the name you registered you will be asked to create a new password and confirm it
(Kindly save your Windows and sql server authentication name somewhere save so you can log in with either whenever you want.)
Importing our database with Pyspark
# Load the pyspark libraries
from pyspark.sql import SparkSession
import pyodbc
import pandas as pd
spark = SparkSession.builder \
.appName("SQL Server to PySpark") \
.getOrCreate()
# Set up the database connection
db_host = "localhost"
db_port = "YOUR TCP/IP PORT NUMBER"
db_name = "YOUR_DATABASE NAME"
db_user = "YOUR_USERNAME"
db_password = "YOUR_PASSWORD"
# Connect SQL Server with Pyspark
conn = pyodbc.connect(
"Driver={SQL Server};"
"Server=" + db_host + "," + db_port + ";"
"Database=" + db_name + ";"
"UID=" + db_user + ";"
"PWD=" + db_password + ";"
)
query = "SELECT * FROM TABLE_NAME"
df_pandas = pd.read_sql(query, conn)
# Convert Data into a Data Frame
df_spark = spark.createDataFrame(df_pandas)
# Read the dataframe
# Print the schema of the DataFrame
df_spark.printSchema()
# Show the first few rows
df_spark.show()
Output from a sample data I used:
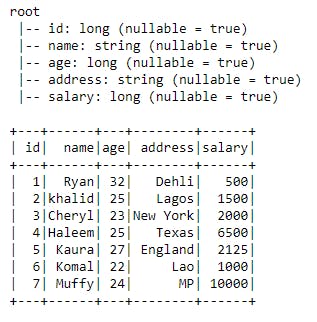
The next Article will be Loading Data From MySQL Database With PySpark